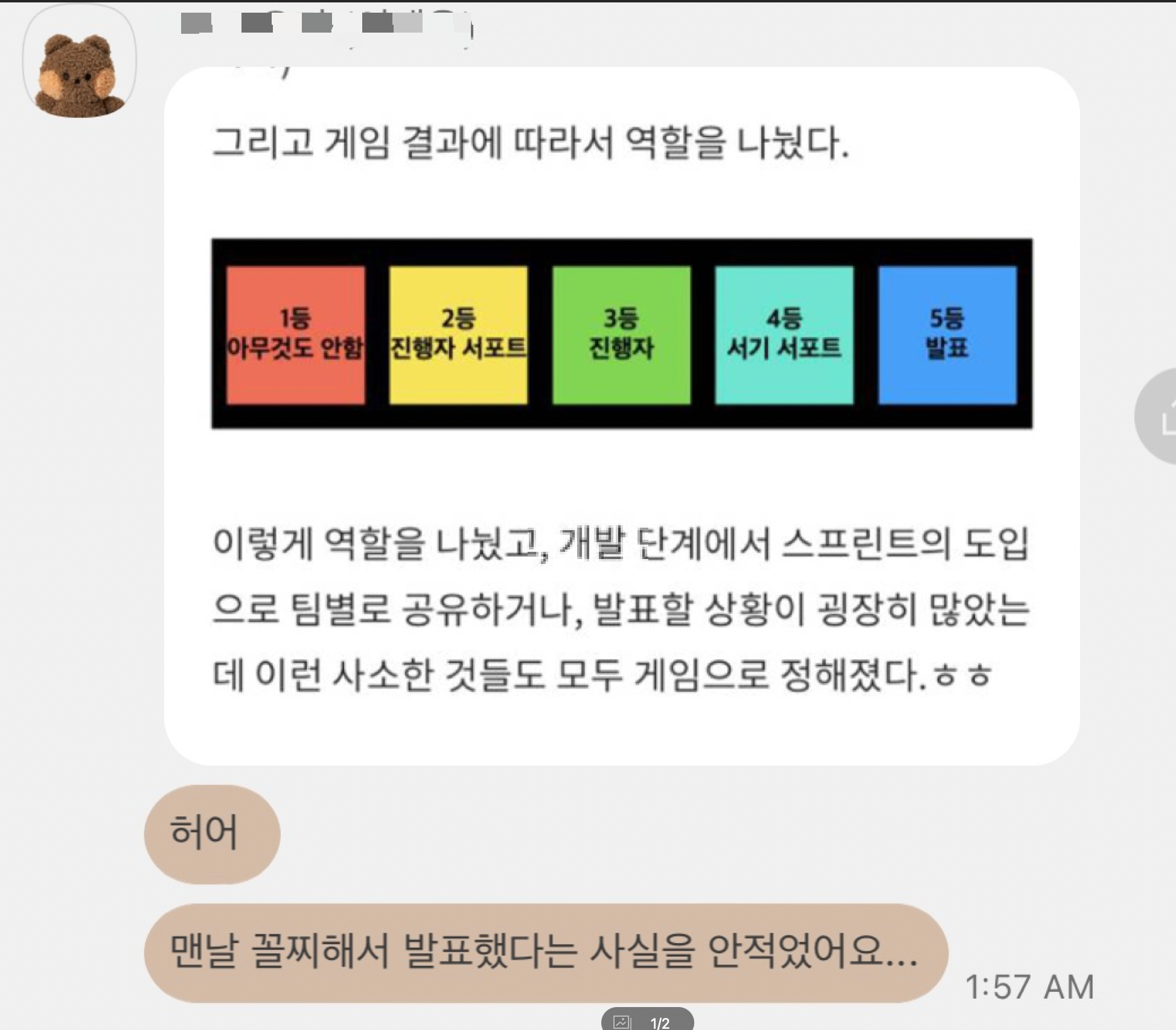
이번 프로젝트에서 원래 하고 싶었던 것은 한국어 말하기 분석이었다. 트로트 가수와 아이돌 가수의 댓글을 학습 데이터로 삼아 두 말투를 구분하는 모델을 만든 뒤 예능 프로그램 댓글에서 두 말투 중 어떤 말투가 많은지 분석하고 해당 예능 시청자를 분석하는 프로그램을 만들고 싶었다. 유튜브 API를 사용하면 댓글 100개를 가져올 수 있었는데 나는 더 많은 댓글이 필요했다. 왜냐하면 아이돌 가수 댓글의 경우 외국어로 된 댓글이 많기 때문에 1만 개의 댓글을 달아야 한국어로 된 댓글 100개를 얻을 수 있기 때문이다. 그래서 스크래핑을 통해 댓글 데이터를 수집하려 했지만 유튜브 댓글은 스크롤을 하지 않으면 나타나 스크롤에 대한 많은 시도를 했지만 60개보다 많은 댓글은 담지 못했다. 직접 스크롤하면서 유튜브 댓글이 나타나는 타이밍을 관찰해 코드에 적용했지만 뜻대로 되지 않았다. 스크롤을 조금씩 낮춰보고 스크롤을 두 번 시도하고 등등…! 네이버 댓글은 한국어인 대신 그 양이 부족해 결국 주제를 바꾸기로 했다.이번 프로젝트는 크게 자연어 처리와 이미지 처리로 나뉘는데, 내 컴퓨터에서 3일 안에 이미지를 다루려면 아무것도 할 수 없다는 생각이 들었다. 그래서 자연어 처리를 하는 방법을 찾아보니 가사 생성 모델이 예로 굉장히 많이 등장했다. 그래서 내가 좋아하는 가수가 좋아하는 앨범의 가사를 넣어서 앨범의 새 트랙을 만들어볼까? 라고 생각하다가 작사만 하면 너무 흔한 프로젝트가 될 것이고 겹치는 주제로 프로젝트를 진행한 사람들이 많은 것 같았다. 그러던 중 작사를 잘하면 작곡도 할 수 있지 않을까 하는 생각이 들었다. 그래서 작사작곡을 다 하자! 에 가려고 했는데…! 작곡 프로그램은 미디 파일을 이용해야 하는데 미디 파일은 취미 생활로 만드는 사람이 많기 때문에 내가 좋아하는 가수 음악인 미디 파일을 찾기는 어렵다고 생각했다. 당시 코딩하면서 피아노 곡을 듣는 것에 빠져 있었는데 피아노 곡은 midi 파일이 많을 거라고 확신해서 이걸 주제로 선정했어!모델을 돌리는 데 5시간씩 걸려 모델을 돌리고 잤는데 그러다 모델 저장에서 오류가 나거나 런타임이 초기화된 콜랩 파일을 세 번 마주했고 결국 모델을 얻는 데 이틀이 걸렸다. 그런데 이렇게 힘들게 얻은 모델의 작곡 결과는 충격적으로 별로였다. 계속 한 음만 반복되는 꽹과리 음악이 흘러나온 것이다. 나는 그 원인이 sequence의 길이에 있다고 생각했고 sequence의 길이를 100에서 10으로 줄였어! 그 결과 학습 속도도 빨라졌을 뿐만 아니라 과적합도 해결되었다!! 그리고 PPT 완성되면 제출일이 되어서 제출했다.이번 프로젝트는 앞뒤로 일정을 잡아놔 실질 프로젝트 기간이 이전 프로젝트의 절반밖에 되지 않았다. 그래서 문제가 발생했을 때 회피해 버리거나(유튜브 댓글 스크래핑) 문제가 해결된 원인을 확실하게 파악하지 못하거나(sequence를 줄여 문제가 해결된 것이 LSTM이 장기간 정보를 저장하기 위해 뒷부분에 한 음 추가됐다고 해서 큰 변화가 없는 결과를 냈기 때문이라고 생각했지만 명확하지 않아 발표 영상에서 언급은 없었다.) 문제를 들여다보지 않은 적도 있다(LSTM 대신 병렬화 가능한 모델을 사용하거나 데이터 파이프라인을 구축하는…). 아쉬움이 남기도 있지만 나머지 섹션 기간 동안 공부할 부분을 발견하려고 한다.<프로젝트PPT>



인기글
![[B2B 마케팅] 마케터가 퍼스트파티 데이터에 주목해야 하는 이유](https://cdn.imweb.me/upload/S202203288ec50bb810720/eedfc252626ce.png "[B2B 마케팅] 마케터가 퍼스트파티 데이터에 주목해야 하는 이유")


 다운: 갤럭시 안드로이드 유튜브 광고 제거 무료")